问题:
[单选,A1型题] 反映抗体滴度资料平均水平,适宜采用的指标是()
算术均数。中位数。几何均数。百分位数。调和均数。
问题:
[单选,A1型题] 下列不属于统计全过程设计内容的选项是()
确定此次研究的观察对象和观察单位。确定获取原始数据的方式。对数据进行假设检验。如何做好组织工作及尽量控制误差。在资料获取并整理完毕之后计划采用何种统计指标。
问题:
[单选,A1型题] 关于变异系数,下面说法错误的是()
变异系数就是标准差与均数的比值。比较同一人群的身高、体重两项指标的变异度时宜采用变异系数。两组资料均数相差悬殊时,不适合用标准差比较其变异程度。变异系数的单位与原始数据相同。变异系数的数值有可能大于1。
问题:
[单选,A1型题] 为全面描述对称(或正态)资料的分布情况,应知道的指标是()
算术均数。标准差。均数与标准差。均数与极差。中位数。
问题:
[单选,A1型题] 某假设检验,检验水准α=0.05其意义是()
不拒绝错误的无效假设,即犯第二类错误的概率是0.05。统计推断上允许犯假阴性错误的概率为0.05。当无效假设正确时,平均在100次抽样中有5次推断是错误的。将实际差异误判为抽样误差的概率是0.05。实际上就是允许犯第二类错误的界限。
问题:
[单选,A1型题] 关于标准正态分布,下列论述错误的是()
标准正态分布又称u分布。μ分布是将正态分布通过公式:u=(
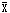
-μ)/σ转换而来。u分布曲线的位置和形状是固定的。任意正态分布均可转换成标准正态分布。u分布的研究仅具有理论意义,但不会用于假设检验等统计分析。
问题:
[单选,A1型题] 估计医学参考值范围时,下面说法错误的是()
"正常人"是指排除了对研究指标有影响的疾病和因素的人。需要足够数量,通常样本含量有100例以上。"正常"是指健康,没有疾病。需要考虑样本的同质性。对于某些指标组间差别明显且有实际意义的,应先确定分组,再分别估计医学参考值范围。
问题:
[单选,A1型题] t检验,P<0.05说明()
两样本均数不相等。两总体均数有差别。两样本均数差别较大。两总体均数差别较大。两样本均数差别有实际意义。
问题:
[单选,A1型题] 已知t0.05,18=2.101(双侧),则区间(-2.101,+2.101)与曲线所围面积是()
95.0%。97.5%。99.0%。2.5%。5.0%。
问题:
[单选,A1型题] 某人算得资料的s=-3.0,可认为()
变量值都是负数。变量值负的比正的多。计算有错。变量值一个比一个小。变量值多数为零。
